
Neuroevolutionary Wordle - Action Space Expansion Shock
Action space expansion shock is an issue I’ve been contending with in my genetic algorithm for Wordle-playing neural nets lately.
The ‘action space’ is the set of words a model knows. These are its possible actions, when it needs to take a turn in a Wordle game. They are also the ’training data’ words that could be used to score the model, in fitness evaluation.
Injection of New Output Embeddings
Injection of new output embeddings, or late action injection, as I have recently started calling it, works as follows:
The model can already look at a Wordle grid and return a latent vector from the top of the policy output head. This vector can be compared to all the output embeddings, to choose an action. To keep things simple, we may think of the latent vector as representing the kind of word the policy wants to play next. The output embeddings each represent a 5-letter word in the model’s vocabulary. Whichever output embedding vector most closely resembles the latent vector is deemed to be the model’s next turn.
We can show a model a partially completed Wordle puzzle. The example puzzle can amount to a massive hint at a new word the model doesn’t know yet. (See augmenting the action space for more information). We can then take whatever latent vector comes of the policy’s output head, and treat that as if it were a new output embedding. This means we can look at what kind of word a model thinks a Wordle grid is hinting at, and use that vector as its internal representation of the new word in future.
How Late Action Injection Is Being Used
There is a phased curriculum of training data. We wish to breed models that have an internal vocabulary of about 2,000 words, but not all at once. We start them off knowing - and being tested against - just 50 words. New shards are introduced at regular intervals.
Action Space Expansion Shock
Looking at the below graph of fitness evaluations over the generations, it is extremely obvious when the action space expansions are happening. They are causing a shock which is dramatically lowering model fitness.
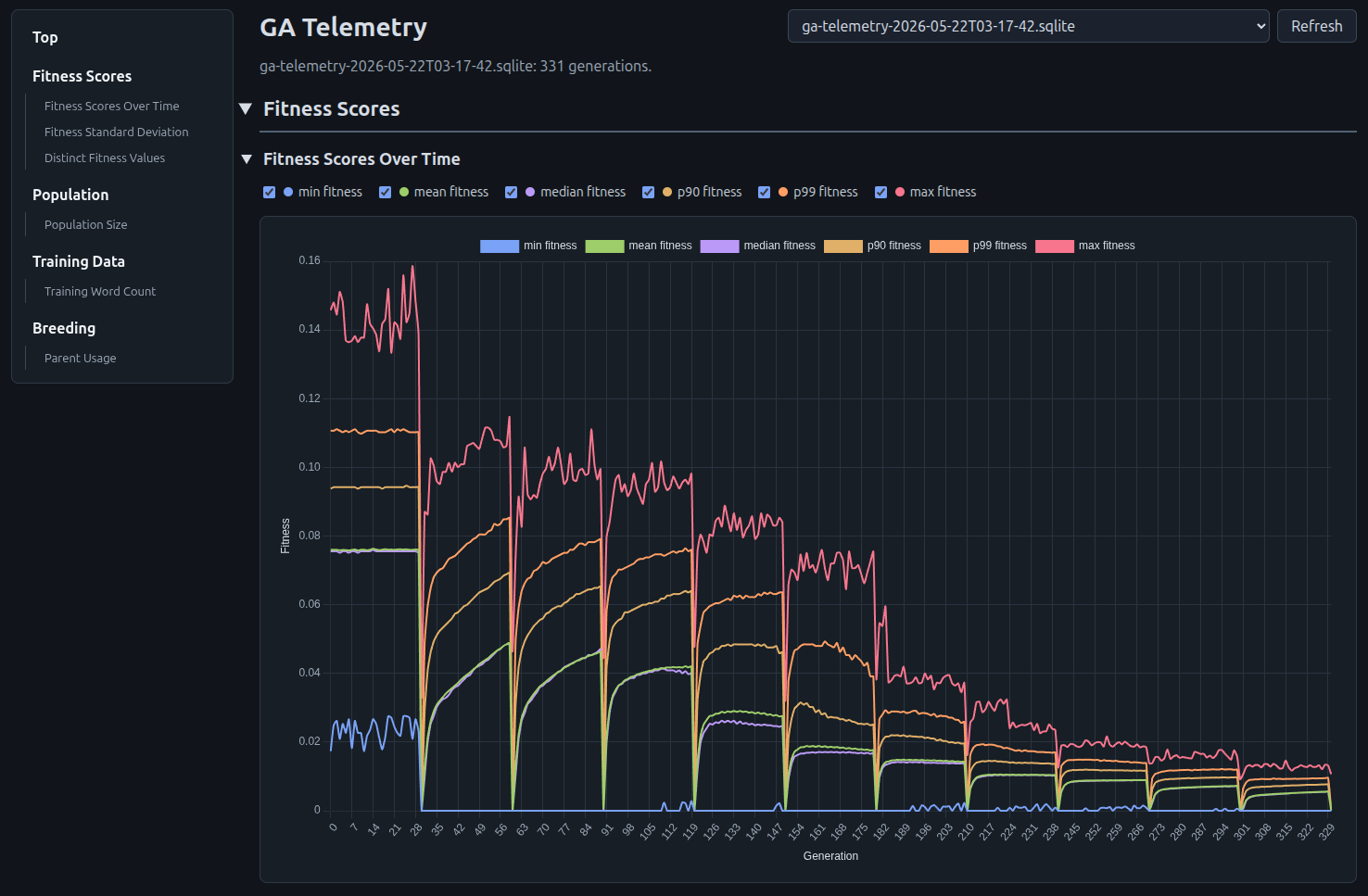
This shows a very clear expansion shock, whenever the output space is made larger. Fitness never really recovers, and the lines go down.
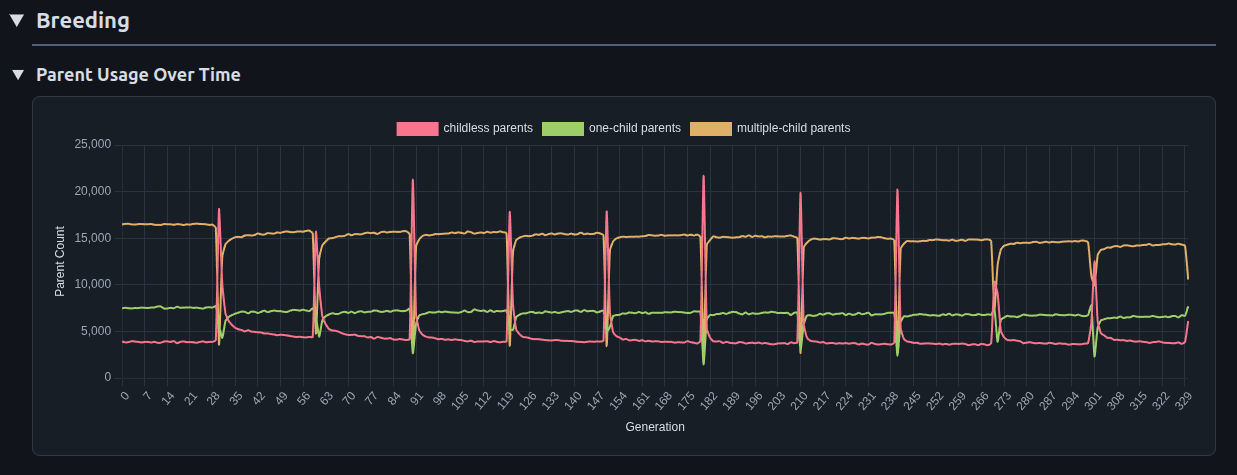
Furthermore, there is at least some evidence that this is creating premature convergence, and a loss of genetic diversity. The number of organisms in a parent generation who die childless has gone up from a pretty low number to about 3/4 of the population in a single generation, at the time of each shock.
Diagnosis
It turns out that the problem is the latent vectors can be too big. Looking at their scalar magnitude, they can be much longer than typical output embeddings. A policy that is immature and not well trained can be quite emphatic like that, and a large output embedding gets selected too often as the next turn.
Add to that the fact that the training data is spatially-aware as well, so most models won’t be tested against the new words right away, and they are way too likely to play words that can’t possibly be the answer.
Cure to Action Space Expansion Shock
Of the 64 dimensions in an output embedding, 38 are trainable. I am ignoring the other 26, because they are just hard-coded letter counts with regards to the 5-letter word the vector represents.
With the 38 trainable parameters, we can pretend that this is a 38-dimensional vector. We can normalise its scalar magnitude to the median length of an existing output embedding, making the new action no more likely that the old ones.
By normalising the length of the new output embeddings at the time of late action injection, we can solve the problem of action space expansion shock.